How Tangle Verifies Work

The hardest question in decentralized infrastructure isn't "how do we run computation" but "how do we know computation ran correctly."
This post covers what each verification mechanism actually proves, where it breaks down, and how Tangle lets developers wire it all together.
Why Not Just Use AWS?
AWS, Google Cloud, and Azure have decades of production hardening, legal accountability, and compliance certifications. For most applications, they're the right choice.
But traditional infrastructure has structural limitations:
Observation risk. Cloud providers have root access to your workloads. Insider threats aren't hypothetical; they're a documented category of breach. For workloads where the data itself is enormously valuable (trading strategies, proprietary algorithms), the risk calculus changes.
Jurisdictional exposure. Cloud providers must comply with legal demands from every government where they operate. Distributed infrastructure across jurisdictions provides options that concentration cannot.
Verification gap. Traditional providers give you audit logs they control. For high-stakes computation, you're trusting reputation rather than cryptography.
Speed of recourse. Contract enforcement takes months. For autonomous systems operating at machine speed, economic enforcement that settles in seconds is the only enforcement that matters.
Where Tangle Fits
Tangle is the general-purpose layer where developers choose and configure verification for each blueprint and service they deploy. We don't prescribe a single verification mechanism. We give you the primitives and let you compose them.
A blueprint that manages signing keys needs MPC. A blueprint running private inference needs TEEs. A blueprint doing deterministic computation can use redundant execution with on-chain result comparison. Tangle supports all of these because different workloads have fundamentally different trust requirements.
The SDK exposes this as a routing and aggregation model. You define job functions, wire them into a router, and configure how many operators need to agree before a result is accepted:
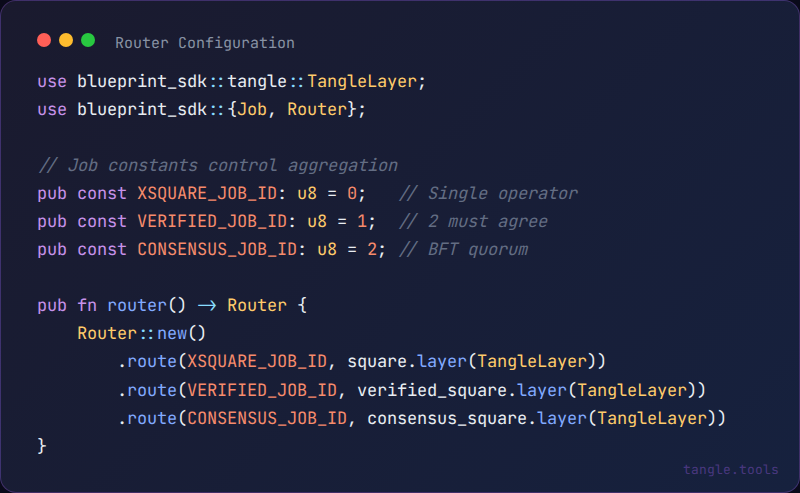
Each route maps a job ID to a handler function wrapped in TangleLayer, which handles ABI encoding/decoding and result submission automatically. The aggregation count (how many operators must submit matching results) is configured per job at the contract level. Same job logic, different verification guarantees.
The runner itself is straightforward:
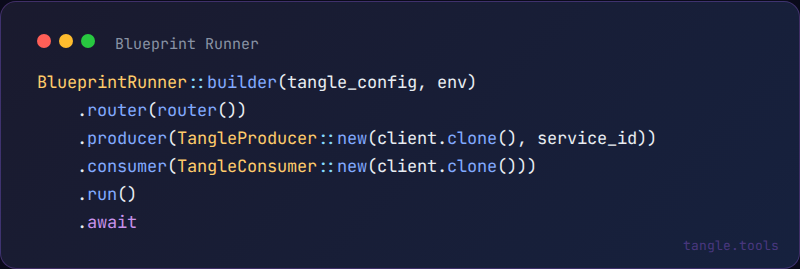
Producer listens for on-chain job submissions. Consumer posts results back. Everything in between is your verification logic.
The Verification Problem
When you pay someone to run computation, you're trusting that they ran the code you specified, on your inputs, and returned the real output. Each verification mechanism proves some of these properties under specific assumptions. None cover everything.
Trusted Execution Environments (TEEs)
TEEs are hardware enclaves that isolate code execution from the rest of the system, including the machine's operator. Intel SGX, AMD SEV-SNP, and ARM TrustZone create isolated memory regions with hardware-enforced encryption. When a TEE boots, it generates an attestation: a cryptographic proof signed by the hardware manufacturer stating what code is running.
What TEEs prove: Specific code is running (via attestation). The operator cannot observe computation (hardware-enforced memory encryption). Inputs and outputs have integrity.
What TEEs don't prove: Code correctness (attestation proves "this code ran," not "this code does what you want"). Side-channel resistance (timing and cache attacks can leak information; practical key extraction from SGX has been demonstrated). Hardware trust (if Intel or AMD are compromised or coerced, attestations become unreliable). Replay resistance (attestations need nonce-based freshness to prevent operators presenting old valid attestations for new requests).
TEEs are appropriate when confidentiality matters more than eliminating all trust, and when side-channel risk is acceptable for your threat model.
Redundant Execution
The simplest verification: have multiple independent parties run the same computation and compare results. N operators execute each job independently. If results match, the job succeeds. Disagreement triggers dispute resolution.
What it proves: At least one honest operator computed correctly (if results match). Collusion requires controlling multiple independent operators. Disagreement is always detectable.
What it doesn't prove: Correctness for non-deterministic computation. Which party is correct during disputes. And it's expensive: running computation 3x costs 3x.
Optimistic Verification with Fraud Proofs
Assume execution is correct, but allow challenges. One operator executes and commits to the result. During a challenge window, anyone can dispute by posting a bond. An interactive bisection protocol identifies the exact divergent instruction. The faulty party loses their bond. This is how Arbitrum and Optimism work.
What it proves: Incorrect execution is eventually detectable and punishable. A single honest verifier is sufficient. Happy path requires only one execution.
What it doesn't prove: Real-time correctness (challenge window delay). Liveness (if no one monitors, fraud goes undetected). Non-deterministic computation (requires deterministic replay).
MPC and ZK Proofs
MPC splits data into shares distributed across parties so they can jointly compute without revealing inputs to each other. No single party learns the inputs (if the corruption threshold holds), but it adds significant overhead and is practical only for high-value computations like key management and threshold signatures.
ZK proofs let a prover demonstrate computation correctness without revealing inputs. Verification is trustless and cryptographically sound. The catch: proof generation is orders of magnitude slower than direct computation, and some ZK systems (Groth16, older PLONK variants) require a trusted setup ceremony. Transparent alternatives (STARKs) avoid trusted setup but produce larger proofs. For ML inference, ZK overhead is currently 10,000-100,000x, though projects like EZKL are pushing this forward.
AI Inference Verification
Neural network inference is mathematically deterministic. The apparent non-determinism comes from temperature sampling, floating-point non-associativity across hardware, and library optimizations like cuDNN algorithm selection. With effort (temperature=0, fixed seeds, deterministic CUDA flags, identical hardware), you can achieve reproducible inference. The non-determinism is a practical constraint, not a fundamental one.
The primary attack vector for AI services is model substitution: claiming to run an expensive model while actually running a cheaper one. Detection techniques include:
Weight hash verification. Hash the model at load time, include the hash in TEE attestation. Verifies model identity at the hardware level.
Challenge prompts (canaries). Specific prompts with known expected outputs. Different models have distinct response patterns. Caveat: sophisticated operators could detect canary patterns and route only those to the real model.
Latency fingerprinting. Different models have characteristic timing profiles. Statistical analysis of response times can detect substitution.
Token probability extraction. For models that expose logprobs, the probability distribution over tokens is a fingerprint.
What remains unsolved: verifying output quality has no cryptographic solution. Detecting subtle degradation (aggressive quantization, caching) requires ongoing monitoring, not one-time verification.
Economics as Backstop
Every verification mechanism has assumptions that can fail. Economics provides the backstop.
The security equation: if P(detection) x slash_amount > profit_from_cheating, rational operators don't cheat.
A worked example: a service processes inference jobs worth $100 each. Operators stake $50,000. Detection mechanisms (TEE attestation, canary prompts, consistency checking) catch cheating 80% of the time within one week. Cheating on 100 jobs might net $5,000 in cost savings.
- Expected value of cheating: $5,000 x 20% = $1,000 (if undetected)
- Expected cost of cheating: $50,000 x 80% = $40,000 (if detected)
Rational operator: doesn't cheat.
This breaks down for irrational actors (nation-states, ideological attackers), correlated failures (volatile staked assets crashing when you need them most), and gray-area cheating (cutting corners in ways that are hard to detect). Economic security addresses catastrophic misbehavior better than subtle degradation.
What Tangle Supports Today vs. What's Coming
What This Means for Builders
Every verification mechanism has trust assumptions. TEEs trust hardware manufacturers. ZK may trust setup ceremonies. MPC trusts honest thresholds. The job is matching the right mechanism to the value of what you're protecting, and being explicit about which assumptions you're making.
Tangle gives you the building blocks. You compose them.
What's Next
The next post covers the developer experience: building blueprints, the SDK, deployment tooling, and the path from idea to production service.
If you're evaluating verification requirements for a specific use case, find us on Discord.
References:
- SGX side-channel attacks: Foreshadow (L1TF)
- MPC protocols: SPDZ paper (Damgård et al.)
- zkML progress: EZKL
Links:
